
概述
这篇paper提出了MEC,一个减少CNN内存占用的方法,同时提升了计算速度,且无精度损失。
读这篇文章的目的是,看看有没有必要将其作为我的Baseline进行比较。
我的工作暂未公开。
贡献点
- 给定内存空间,可以训练或推理更大的模型
- 可以允许更大的mini-batch size
- 通过提高内存子系统的效率加速计算(提高缓存命中)
详细算法
Motivation
im2col的优缺点
im2col的原理图如下图所示。
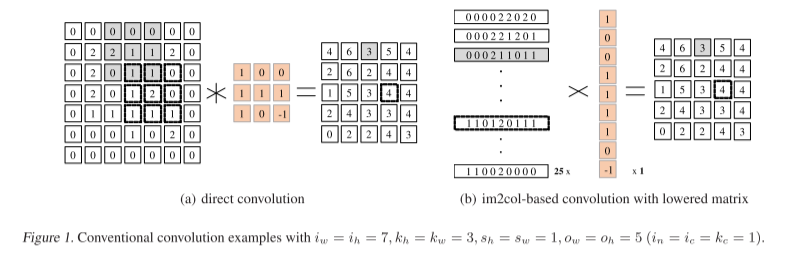
- 优点: 把卷积操作的子矩阵和卷积核的点积运算改为两个一维向量的计算,使用cuBLAS库,可以加速运算。
- 缺点:原本输入矩阵的大小为7 * 7, 而现在的大小为25 * 9, 远远超过原矩阵的大小,带来额外内存开销
MEC主要目标使使用更少的内存开销,执行相同的卷积,同时提升卷积效率。
MEC Overview
im2col算法内存开销大的主要原因是,当卷积步长$s_w$和$s_h$小,而卷积核尺寸K大时,lowered matrix中存在大量冗余。(lowered matrix即上图b中 25 * 9 的剧矩阵)
因此,为了减少存储开销,至关重要的是降低lowered matrix中的冗余量,并保持这种计算模式(不然会降低计算速度)。
MEC 通过一次降低多个列而不是单独的卷积核大小的子矩阵来克服这些挑战,核心思想和细节如下图所示。
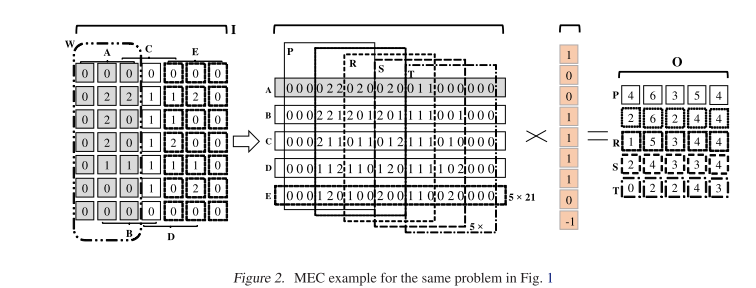
MEC复制W(上图阴影部分(7 x 3的矩阵)), 然后展平为一行如中间矩阵最上方的的A(1 X 21)所示。
A = I[0:7, 0:3]
然后滑动W一个$s_w$的步长,得到B
B = I[0:7, 1:4]
重复此步骤得到矩阵L{A, B, C, D, E} , 5 X 21 的尺寸。
比图1 中的25 x 9 小了54%
这样,L和K的计算方式和im2col完全不同。所以MEC又在L中建立了另一个垂直分区的集合{P,QR,S,T}. 每个分区的大小是$o_w x k_h x k_w$ 即 5 x 9.每个子序列可以通过通过P往右滑动$s_h x k_w$(这里是3)个步长得到.
P = L[0:5, 0:9], Q = L[0:5, 3:12]
这样就可以5个分区{P,Q,R,S,T}就可以使用BLAS计算,计算复杂度与im2col相同。
实际上,MEC直观上消除了im2col卷积中垂直方向的冗余
但是从I复制到L, 那峰值内存占用就是I+L,而普通卷积没有L的存在
MEC 算法
扩展算法1到算法2展示完整的MEC,主要表现在以下几个方面:
- 处理通道
- 处理batch size
然后讨论深度学习背景下的实现细节(主要关于图像格式问题), 对我不太重要,不涉及 如何降低内存。
分析
这节分析了相比于im2col,MEC减少了多少内存占用。

总结
MEC 关注的是单次卷积计算的内存开销
而且MEC的Baseline 是一些卷积的加速算法,例如im2col.
im2col本身就会有额外内存开销,并且MEC只是比im2col的内存开销降低了,并没有比传统CNN卷积方式降低内存开销。
im2col的实验也是关注的单次卷积操作的开销。
而我们的方法注重的是CNN训练过程中的中间结果的内存累积的开销。关注点不在同一层面,无法作为我们的baseline.
参考文献
[Cho, Minsik, and Daniel Brand. “MEC: Memory-efficient convolution for deep neural network.” International Conference on Machine Learning. PMLR, 2017.](MEC: Memory-efficient Convolution for Deep Neural Network (acm.org))
- 本文链接: http://blogs.yovr.top/Paper-Reading-MEC-Memory-efficient-Convolution-for-Deep-Neural-Network/
- 版权声明: 本博客所有文章除特别声明外,均默认采用 CC BY-NC-SA 4.0 许可协议。
